Survey K8s Kafka Memory Usage
此篇文章將探討將分享我在 Strimzi (Kafka in Kubernetes) 中,遇到 cluster 內某一 broker 的 memory usage 特別高的問題。
環境描述
Strimzi 是透過 helm 安裝於 GKE 上,而 CRD KafkaNodePool 設定為 3,意味著會有 3 個 broker。
| environment | version | description |
|---|---|---|
| Kubernetes | v1.30.2 | Google Kubernetes Engine (GKE) |
| Strimzi | 0.42.0 | chart version |
| Kafka | 3.7.1 | metadataVersion: 3.7-IV4 |
問題描述
在 Google Monitoring 上看到一個奇怪的現象,3 個 broker 中有一個 pod 的 memory usage 特別高。由於 Kafka 並未調整特別的參數,以下是已知的 resource 配置:
| resource | value | description |
|---|---|---|
| Pod CPU Request & Limit | 500m | |
| Pod Memory Request & Limit | 2Gi | |
| JVM | -Xmx1G -Xms1G | KAFKA_HEAP_OPTS |
memory usage 及 storage usage 如下:
| name | memory usage | storage usage |
|---|---|---|
| broker-1 | 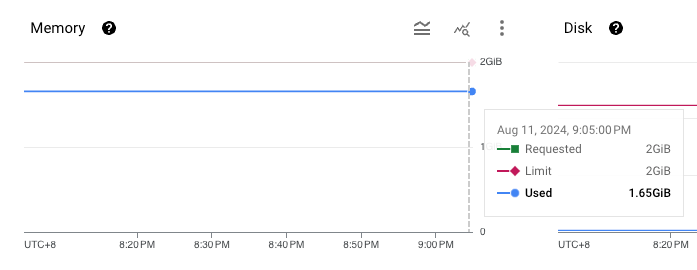 |
 |
| broker-2 | 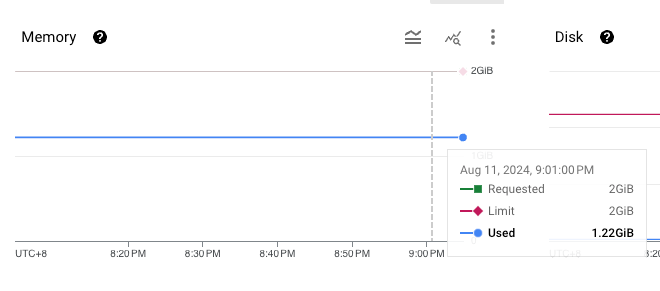 |
 |
| broker-3 | 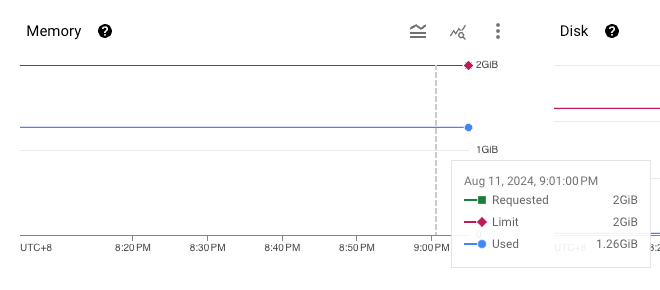 |
 |
從上圖可以看到,在 storage usage 相同的情況下 (broker 內幾乎沒有資料,因為資料已經超過 retention time),也沒有任何 networking traffic,但 broker-1 的 memory usage 就是比較高。
調查過程
在不同 container 內,分別使用以下指令進行調查:
| command | description |
|---|---|
du -sh /var/lib/kafka/data-0 |
查看 kafka 內的 storage usage |
cat /proc/694/status | grep VmRSS |
查看 process 694 使用的記憶體,因 Strimzi 的 Kafka 原理是透過執行 shell script 啟動 java 運行 kafka,而 java 的 pid 是 694 |
cat /sys/fs/cgroup/memory.stat | grep -E 'active_file' |
查看 container 內 cgroup 紀錄的 memory 使用量 (特別篩選 active file,此為 memory 存放於 disk 的 cache) |
cat /sys/fs/cgroup/memory.stat |
查看 container 內 cgroup 紀錄的 memory 使用量 |
以下是我執行指令後的截圖 (圖片非常不清晰,請見諒,但這不影響我最後的結論):
| name | details | description |
|---|---|---|
| broker-1 | 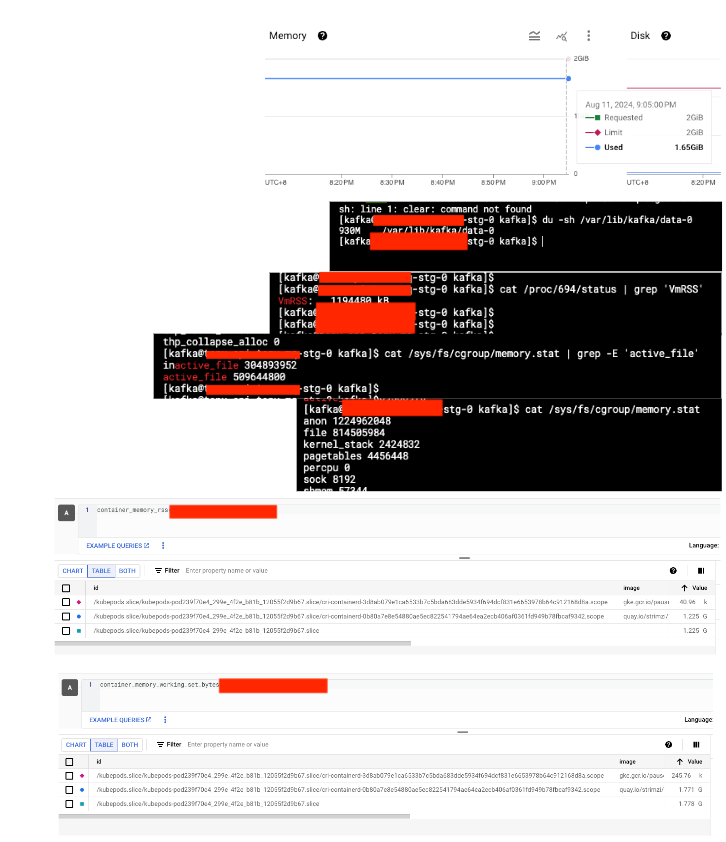 |
active_file: 509644800 container_memory_rss: 1.2G container_memory_working_set_bytes: 1.7G |
| broker-2 | 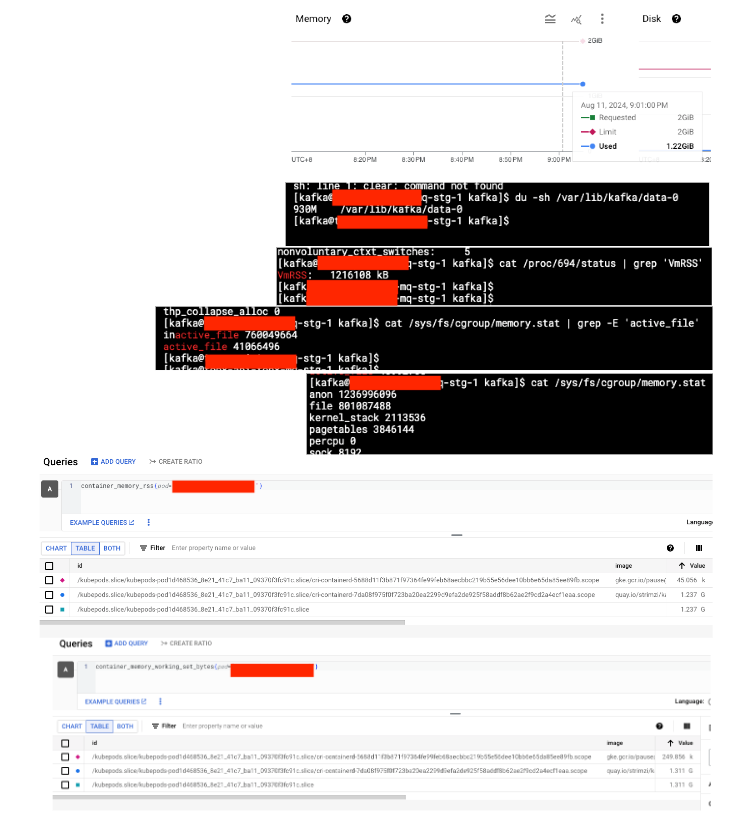 |
active_file: 41866496 container_memory_rss: 1.2G container_memory_working_set_bytes: 1.3G |
| broker-3 | 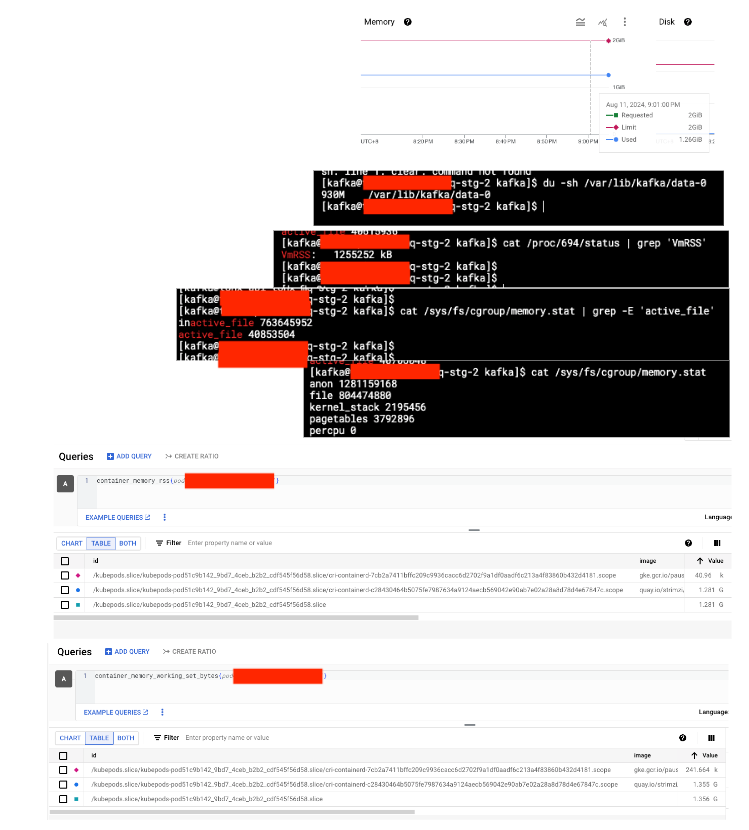 |
active_file: 40853504 container_memory_rss: 1.2G container_memory_working_set_bytes: 1.3G |
從上表可以得知,broker-1 的 active_file 特別高,而 3 個 pod 的 container_memory_rss 是相同的。在 kubernetes 中,計算 Pod memory 的公式如下:
container_memory_usage_bytes = container_memory_rss + container_memory_cache + kernel memory
container_memory_working_set_bytes = container_memory_usage_bytes - total_inactive_file (unactivated anonymous cached pages)
其中,container_memory_working_set_bytes 用於計算 Pod 是否會 OOM,而它包含 cache pages。這是 linux kernel 的一種機制,讀取硬碟資料時,會將一部分的資料存放於 memory 中,加速讀寫速度,並根據 memory 實際使用量,動態調整 cache page 的大小。
調查結果
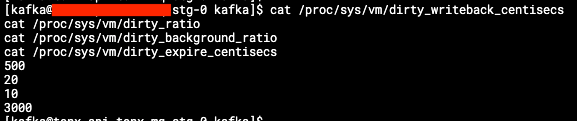
理論上,kernel 動態調整機制,不會造成 memory 不足的問題,但為了降低風險,根據 Linux Kernel 的說明文件,可以手動調整參數,關閉這個功能,不過這在 container 內不可用,原因是權限不足:
https://www.kernel.org/doc/html/latest/admin-guide/sysctl/vm.html#drop-caches
雖然不可以避免 cache page 的產生,但也不需要太擔心,根據 Kafka 的文件,預設的 graceful shutdown 參數為 true,理論上該機制會在 process 關閉前,將資料寫進硬碟,不會造成服務重啟時的損壞。
https://github.com/orgs/strimzi/discussions/6837
如果仍然擔心 memory 不足所帶來的影響,也可以提高記憶體,並修改 KAFKA_HEAP_OPTS 參數,增加 JVM 的記憶體,或者參考 Kafka 關於持久化資料的文章:https://kafka.apache.org/documentation/#persistence
