Calico Multiple Network Interface
在使用 Calico CNI 的 k8s node 上加入多個 network interface
這篇文章將介紹客戶端的 Kubernetes Cluster 上遇到的網路問題,調查後發現是 Calico CNI 在多個 network interface 的 node 上,需要進行特別的設定。
事件發生
某日客戶回報 Kubernetes Cluster 上,一些 pod 溝通時會發生 connection timeout,調查後發現似乎與 DNS 異常有關係,但並沒有找到具體的原因。
調查經過
客戶在使用 ArgoCD 時,發現許多 repository 無法正常 connect,在調查 Pod argocd-repo-server 的 logs 中,出現以下的 error message:
Failed to resync revoked tokens. retrying again in 1 minute: dial tcp: lookup argocd-redis on 10.96.0.10:53
IP 10.96.0.10 是 CoreDNS 預設的 IP,而 argocd-redis 是 ArgoCD 所部署的一個服務,從 error message 可以看出,argocd-repo-server 無法與 argocd-redis 溝通,但背後的 IP 是 CoreDNS,換句話說,argocd-repo-server 無法連上 CoreDNS。
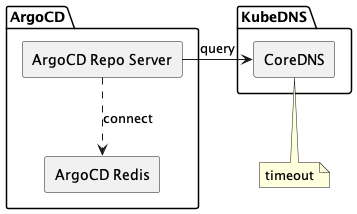
進一步調查後,發現整個 cluster 存在以下幾點事實:
- 大部分需要訪問
CoreDNS的服務會有連線 timeout 的問題,無法與 dns 溝通。 - 不需要訪問
CoreDNS的服務皆正常。 - 若服務與
CoreDNS相同節點的服務,無論是否需要與CoreDNS溝通,皆正常。 - node 與 node 間可以互相溝通,包含
CoreDNS所在的 node。 - pod 與 pod 間可以互相溝通,但
CoreDNS所在的 node 上面的 pod,如果不是設定hostNetwork: true,就無法與其他 pod 溝通。
問題是突然發生的,有詢問客戶是否在問題發生的前後時間點,對 Kubernetes 做任何調整,結果是沒有。於是我嘗試進行以下的操作,但仍然無法解決問題:
- 重新設定 kube-proxy
- 重起 CNI DaemonSet Pods
經過各種測試及排查,基本上可以判定,此問題與 IPVS, IPTables, Network Policy 等設定無關,而在 calico 的 DaemonSet Pods 重啟後,可能會發生以下問題,需要手動刪除 calico 在 node 上加入的 network interface,才可以正常 Running:
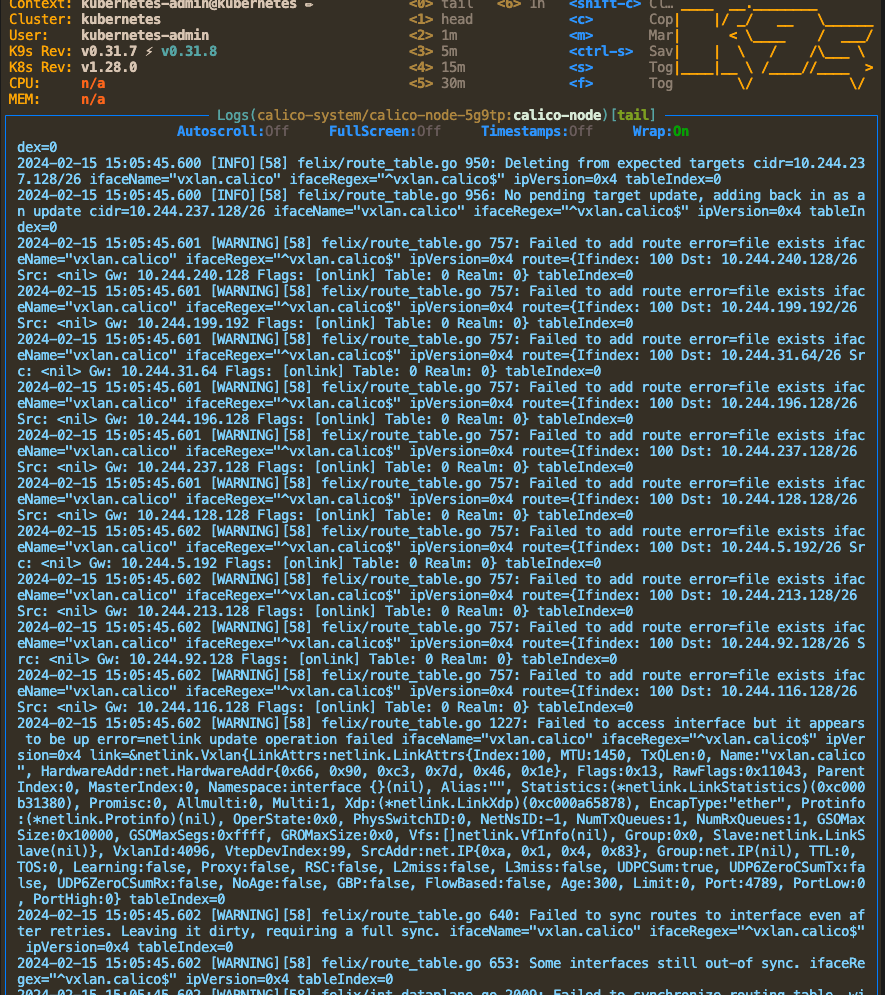
在手動刪除 network interface 時發現一件事, CoreDNS 所在的 node 相較於其他 node,多出了一個 network interface,而客戶所使用的 Hypervisor 是 Proxmox,在 GUI 上可以看到,確實 node 被加入新的 Network Device:
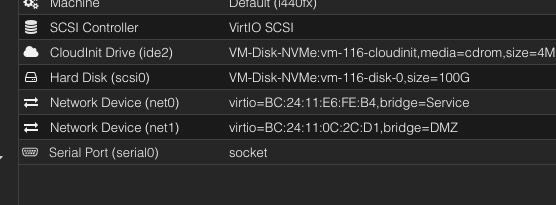
換句話說,node 現在有多張網卡,可能就是錯誤發生的原因。
解決問題
與客戶同步後,確認這個 Network Device 是客戶為了連線到不同網段的設備而加入,且不同網段間,是無法互相溝通的,這可能是造成這次事件的原因,客戶確實沒有調整 Kubernetes 的設定,而是直接更動設備。
閱讀 Calico 的文件後,可以從以下架構得知,calico 會在多個節點上,設定 IP 建立 BGP route sharing:
https://docs.tigera.io/calico/latest/reference/architecture/overview
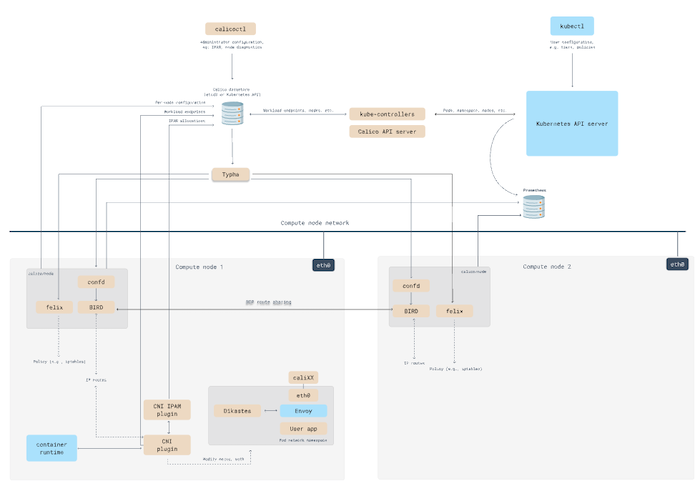
如果 node 上有多個 network interface,則需要在 DaemonSet Pod 上修改 env IP_AUTODETECTION_METHOD,否則預設的 first-found 會使用程式第一個找到的 network interface 所設定的 IP 建立 BGP route sharing,目前遇到的問題看起來是 Calico 使用錯誤的IP:
https://docs.tigera.io/calico/latest/reference/configure-calico-node#configuring-bgp-networking

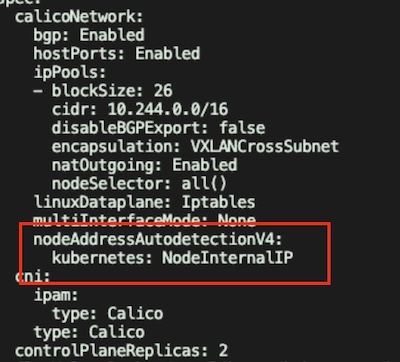
可以透過 官方教學 在 Calico 的 CRD Installation 上設定 nodeAddressAutodetectionV4 為 NodeInternalIP,這樣就會在 DaemonSet Pod 上加入 IP_AUTODETECTION_METHOD 設定,使用當初建立 Kubernetes 的 Node IP 建立 BGP route sharing:
結論
事件發生的原因是,客戶增加了一張網卡在 node 上,導致 Calico 抓取錯誤的 IP 建立 BGP route sharing,由於環境設定,不同網段的 IP 無法溝通,且 CoreDNS 剛好在這台 node 上,這影響所有需要使用 DNS 的服務,與 CoreDNS 同一個 node 上的服務則因為不需要與其他 node 溝通,因此不受影響,另外,有設定 hostNetwork: true 的 Pod ,因為是使用與 node 相同的 network namespace,可以透過正確的 network interface 與其他 node 溝通,也不受事件影響,這大大增加排錯的難度。
未來遇到突發狀況時,除了調查事件發生的時間點前後,Kubernetes 的操作外,也要調查 device 是否有改變。
